Latest
Why are we still using a dated GPT-4 benchmark score?
Aug 29, 2023 • Desmond Grealy
Appreciation
First off: Meta AI and the WizardLM / WizardCoder teams mentioned here deserve massive kudos for their recent contributions (Code Llama & WizardCoder-Python-34B). They're doing great things for the common good, and that deserves a lot of appreciation. Thank you, Meta AI, and Wizard Coder researchers.
GPT-4's HumanEval is at 82.0
According to Meta AI, this chart shows the performance of the new Code LLama foundation model family on two prominent benchmarks of coding ability: HumanEval (Chen et al. 2023) and MBPP (Austin et al. 2022). It is interesting that the performance of GPT-4 on HumanEval looks wrong:
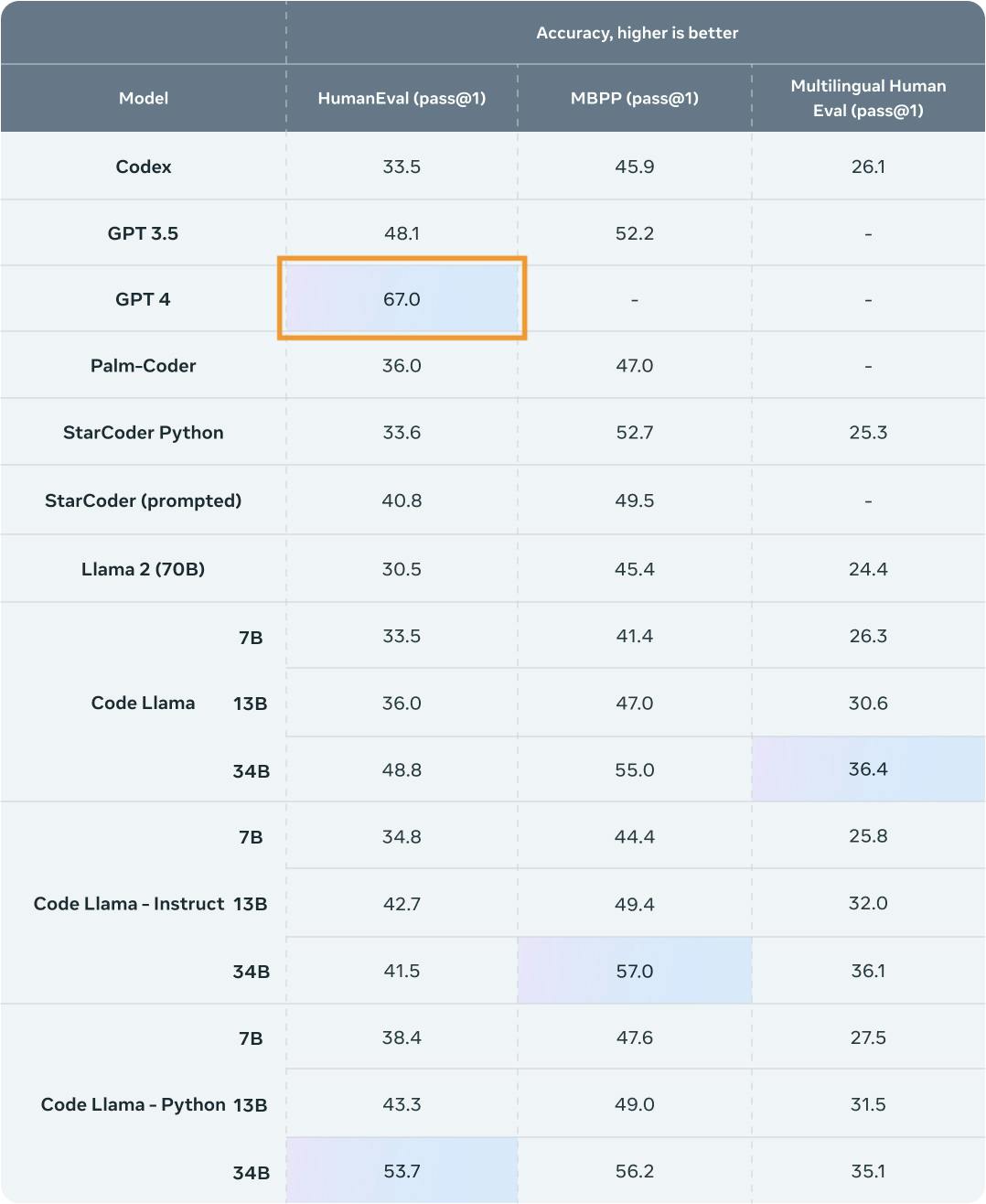
I see some people calling this disingenuous, so I wanted to figure out what was going on. From what I can tell the chart is reporting the 67.0 HumanEval score from the introductory GPT-4 Technical Report (OpenAI 2023) in March 2023:
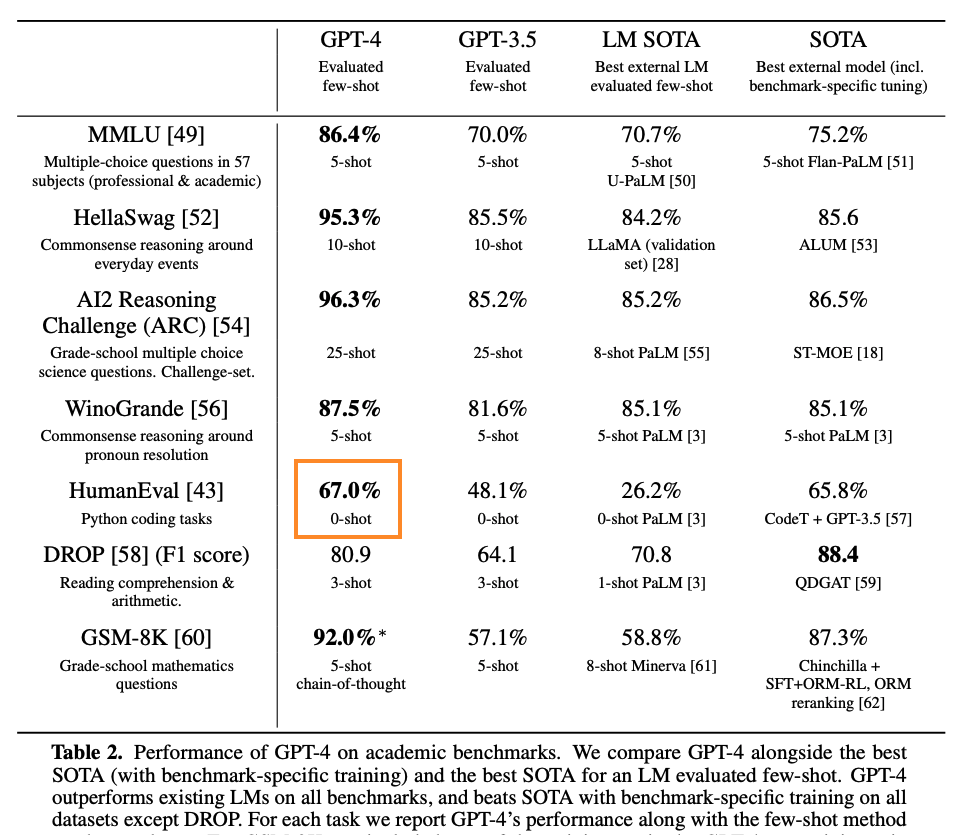
But only a week later, the HumanEval 0-shot pass@1 score was updated from 67.0 to 82.0 in the "Sparks of AGI" paper (Bubeck et al. 2023).

Back then, people noticed the jump and wondered about it, I remember. API keys for GPT-4 were not available at the time, and Microsoft Research apparently had access to a a beta version anyway, so everyone just had to take their word for it. But access to GPT-4 has been available for a while now, and there has been ample opportunity to make measurements. I believe the first production version of GPT-4 was performing at 67.0 as reported in their initial technical report, but performance has been higher for several months. It's difficult to pinpoint because OpenAI never communicated it.
So, why did the Code Llama team compare against a lower number for GPT-4? There's a knee-jerk reaction to say this is from bias and that they are being intentionally misleading. However, I think it's entirely possible that when their research started, there was a preference to report only what OpenAI has itself reported since the "sparks" paper was not authored directly by OpenAI, but instead by (the albeit closely affiliated) Microsoft Research. There could have been reluctance to cite this paper for other reasons: many people didn't care for it and thought it was more marketing than science. I would say it was still a credible measurement from a widely read paper, but it wasn't immediately verifiable, and when it did become verifiable is unclear.
It's also possible there was some error propagation, if you expect that others must have already done the measurement, as Meta AI isn't alone in the mistake. I have noticed other papers doing the same thing, for instance WizardCoder (Luo et al. 2023) also competed against the inaccurate 67% GPT-4 score despite the newer performance I believe being available (?) at the time of publishing (see pg 6 of the WizardCoder paper cited above). Although the WizardCoder team definitely mentions the correct score in later communications.
Whoops
I sympathize with the researchers. It can be tedious to verify every reported metric about other people's projects, when there are already a hundred tests and verifications you're running to do your own research. It's easy to just report what you see a few other papers agreeing on.
I suppose it's also a bit annoying to have to pay OpenAI inference fees to do an evaluation on their model. They know they are in the lead, and that everyone needs to have an accurate up-to-date score for benchmarking. It would have been more convenient and the mistake could have been avoided if OpenAI had published the 82.0 themselves, anywhere.
But GPT-4 is (currently) the model to beat in this field so let's have our facts about it accurate.